
Downtime is the bane of every business, especially in today’s digital world. When your servers go down, you lose access to critical data, your website becomes inaccessible, and your productivity grinds to a halt. This can result in lost revenue, damaged reputation, and unhappy customers. In this article, we’ll explore the importance of server uptime for businesses, and discuss practical strategies to protect your business from server downtime. We’ll cover topics such as choosing the right hosting provider, implementing robust monitoring systems, and having a disaster recovery plan in place. By taking these steps, you can minimize the impact of server downtime and keep your business running smoothly.
Understanding the Impact of Server Downtime
Server downtime, the period when a server is unavailable, can have a significant impact on businesses and organizations. It can lead to disruptions in operations, loss of revenue, damage to reputation, and even legal consequences. This article will delve into the various impacts of server downtime and explore strategies to minimize its occurrence.
Financial Consequences
Server downtime can result in substantial financial losses for businesses. The loss of productivity during downtime translates to lost revenue. E-commerce businesses, in particular, can experience a significant drop in sales during periods of server unavailability. Additionally, businesses may face costs associated with restoring lost data, repairing damaged equipment, and compensating customers for any inconvenience caused by the downtime.
Customer Dissatisfaction and Reputation Damage
Downtime can severely impact customer satisfaction and damage a company’s reputation. When customers are unable to access vital services or information, frustration and dissatisfaction can arise. Negative reviews and social media posts can spread rapidly, tarnishing the company’s image and eroding customer trust.
Operational Disruptions
Server downtime can disrupt various operational processes, including:
- Email communication: Loss of access to email can significantly impede communication with customers, employees, and partners.
- Website and online services: Website and online service outages can hinder business transactions, customer support interactions, and internal workflows.
- Data access and processing: Downtime can lead to disruptions in data access, impacting critical business functions like reporting, analytics, and decision-making.
Legal Implications
In certain industries, server downtime can have legal implications. For example, healthcare organizations may face legal action for failing to maintain patient records securely, while financial institutions may face penalties for breaching data privacy regulations.
Minimizing Server Downtime
Several strategies can be implemented to minimize server downtime:
- Regular maintenance and updates: Keeping software and hardware up to date can prevent security vulnerabilities and system failures.
- Redundancy and failover systems: Having redundant servers and failover systems ensures that if one server goes down, another can take over seamlessly.
- Monitoring and alerting systems: Real-time monitoring and automated alerts can help identify potential problems before they escalate into downtime.
- Disaster recovery plan: Having a well-defined disaster recovery plan outlines the steps to be taken in case of a major outage, including data backups and recovery procedures.
- Cloud-based solutions: Utilizing cloud services can provide enhanced resilience and scalability, minimizing the impact of server issues.
Conclusion
Server downtime can have a significant impact on businesses and organizations, leading to financial losses, customer dissatisfaction, operational disruptions, and legal consequences. By implementing proactive strategies for prevention, monitoring, and recovery, organizations can minimize the occurrence and impact of server downtime, ensuring business continuity and customer satisfaction.
Causes of Server Downtime
Server downtime can be a major headache for any business. It can disrupt operations, lead to lost revenue, and damage your reputation. But what causes server downtime in the first place? In this article, we will explore some of the most common reasons for server downtime and what you can do to prevent it.
Hardware Failures
One of the most common causes of server downtime is hardware failure. This could be anything from a faulty hard drive to a power supply that goes out. Hardware failures can be difficult to predict and can happen at any time. However, there are a few things you can do to mitigate the risk of hardware failures:
- Use high-quality hardware: Invest in reliable hardware from reputable manufacturers.
- Implement redundancy: Use multiple servers or components to ensure that if one fails, the others can take over.
- Regularly monitor your hardware: Use monitoring tools to keep an eye on your server’s health and identify potential problems before they become critical.
Software Errors
Another common cause of server downtime is software errors. These errors can be caused by bugs in the operating system, applications, or even configuration errors. Software errors can be difficult to debug, and they can often be triggered by unforeseen circumstances. To prevent software errors, you can:
- Use updated software: Make sure your operating system and applications are up to date with the latest security patches and bug fixes.
- Test your software thoroughly: Before deploying any new software, test it thoroughly to make sure it’s stable and reliable.
- Have a rollback plan: In case of a major software error, you should have a plan to quickly roll back to a previous working version.
Network Issues
Network issues can also cause server downtime. These could be anything from a broken network cable to a denial of service (DoS) attack. To prevent network issues from causing downtime, you can:
- Use a reliable network provider: Choose a network provider with a strong track record of reliability.
- Have multiple network connections: Use multiple network connections to provide redundancy in case one connection fails.
- Implement network security measures: Protect your network from unauthorized access and DoS attacks.
Human Error
Don’t underestimate the power of human error. Sometimes, server downtime is caused by accidental configuration changes or misconfigurations. To prevent human error, you can:
- Train your staff: Make sure your staff is properly trained on how to manage your server and troubleshoot problems.
- Implement change management procedures: Have a process for making changes to your server, including approvals and testing.
- Use automation: Automate routine tasks to reduce the risk of human error.
Natural Disasters
Finally, natural disasters can also cause server downtime. This could be anything from a power outage to a fire or earthquake. To protect against natural disasters, you can:
- Use a disaster recovery plan: Have a plan in place for how to recover your server in case of a disaster.
- Use a data backup solution: Regularly back up your data to an offsite location.
- Consider using a cloud provider: Cloud providers offer a high degree of redundancy and disaster recovery capabilities.
By understanding the common causes of server downtime and taking steps to prevent them, you can minimize the impact of downtime on your business and keep your servers running smoothly. Remember, prevention is always better than cure.
Proactive Measures to Prevent Downtime
Downtime is a significant issue for any business, as it can lead to lost productivity, revenue, and customer satisfaction. It is essential to take proactive measures to prevent downtime and ensure business continuity. Here are some key strategies to consider:
1. Regular Maintenance and Updates
Regular maintenance and updates are crucial for preventing downtime. This includes:
- Software updates: Regularly updating software and operating systems helps patch security vulnerabilities and improve performance.
- Hardware maintenance: Performing regular checks and maintenance on hardware, such as servers and network devices, can identify potential issues before they lead to downtime.
- Backup and Disaster Recovery: Implementing a robust backup and disaster recovery plan is critical for business continuity. This involves creating regular backups of data and having a plan in place to restore systems quickly in case of a disaster.
2. Monitor System Performance
Monitoring system performance allows you to identify potential problems before they escalate into downtime. This can be achieved through tools that track:
- Resource utilization: Monitoring CPU, memory, and disk usage can help identify bottlenecks and resource constraints.
- Network performance: Tracking network latency and bandwidth usage can pinpoint connectivity issues.
- Application performance: Monitoring response times and error rates can highlight performance problems within applications.
3. Employee Training and Awareness
Training employees on best practices and procedures related to system usage and security can significantly reduce the risk of downtime. This includes:
- Security awareness: Educating employees on common security threats and how to protect against them can prevent malicious attacks.
- Proper system usage: Training employees on the correct way to use software and hardware can minimize user errors.
- Incident reporting: Encouraging employees to report any unusual system behavior or security incidents promptly can help address problems before they lead to downtime.
4. Implement Redundancy
Redundancy is essential for ensuring business continuity in case of a failure. This involves having backup systems and components in place to take over if the primary system fails. Consider implementing:
- Server redundancy: Having multiple servers running the same applications or data can ensure that the service remains available even if one server fails.
- Network redundancy: Implementing multiple network connections and routers can provide failover capabilities in case of a network outage.
- Data redundancy: Having multiple copies of data stored in different locations can protect against data loss due to hardware failure or disaster.
5. Conduct Regular Drills and Testing
Regularly testing your backup and disaster recovery plans is crucial for ensuring their effectiveness. This involves conducting drills and simulations to ensure that:
- Backup processes: Regularly testing backups to ensure they are complete and can be restored successfully.
- Disaster recovery procedures: Simulating disaster scenarios to ensure that employees know how to respond effectively and restore systems quickly.
- System recovery time: Measuring the time it takes to restore systems after a failure and identifying areas for improvement.
By implementing these proactive measures, businesses can significantly reduce the risk of downtime and ensure business continuity. Regular maintenance, system monitoring, employee training, redundancy, and testing are all essential steps for preventing downtime and minimizing its impact on operations.
Implementing Data Backup and Disaster Recovery Solutions
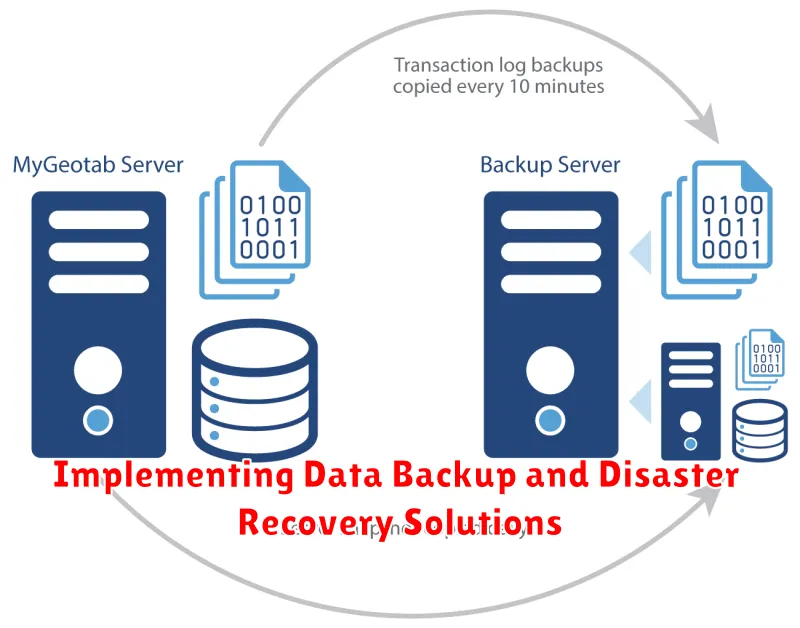
In today’s digital age, data is the lifeblood of any organization. It’s crucial to ensure the safety and availability of your data, even in the face of unexpected events like natural disasters, cyberattacks, or hardware failures. Implementing robust data backup and disaster recovery (DR) solutions is not just a best practice, it’s a necessity.
Understanding the Importance of Backup and DR
Data Backup involves creating copies of your data and storing them in a separate location. This ensures you have a safe copy of your data in case of an incident. Disaster Recovery, on the other hand, is a plan and process that helps restore your business operations and critical data after a disaster. It involves restoring data from backups, setting up alternative systems, and ensuring business continuity.
Key Elements of a Comprehensive Backup and DR Strategy
A well-designed backup and DR strategy should encompass several key elements:
- Data Identification: Define what data is critical and must be backed up.
- Backup Methods: Select appropriate backup methods like full backups, incremental backups, or differential backups.
- Backup Storage: Choose suitable backup storage options, such as tape drives, hard drives, cloud storage, or a combination of these.
- Recovery Testing: Regularly test your backup and recovery processes to ensure effectiveness.
- Disaster Recovery Plan: Develop a detailed disaster recovery plan outlining procedures for data restoration and business resumption.
Types of Backup and DR Solutions
There are various types of backup and DR solutions available, each with its advantages and disadvantages. Some common solutions include:
- On-premises Backup: Traditional backup solutions using local servers and storage.
- Cloud Backup: Utilizing third-party cloud services for backup and recovery.
- Hybrid Backup: Combining on-premises and cloud storage for optimal cost and security.
- Disaster Recovery as a Service (DRaaS): Outsourcing disaster recovery to a service provider.
Benefits of Implementing Backup and DR Solutions
Implementing comprehensive backup and DR solutions provides numerous benefits, including:
- Data Protection: Safeguarding your data against loss due to various threats.
- Business Continuity: Minimizing downtime and disruption during outages.
- Compliance: Meeting industry regulations and standards.
- Cost Savings: Preventing financial losses from data loss or downtime.
- Peace of Mind: Providing confidence in the resilience and security of your data.
Conclusion
In conclusion, implementing data backup and disaster recovery solutions is an essential investment for any organization. By safeguarding your data and ensuring business continuity, you can mitigate risks, improve efficiency, and maintain a competitive edge in today’s dynamic digital landscape.
Investing in Redundant Server Infrastructure
In the digital age, businesses rely heavily on their server infrastructure to function. Downtime can be costly, leading to lost productivity, revenue, and customer satisfaction. A robust server infrastructure is essential for ensuring business continuity and resilience. One crucial aspect of this robustness is the implementation of redundancy.
Redundancy, in the context of server infrastructure, refers to having backup systems and components in place to take over in case of a failure. This could include multiple servers, network connections, power sources, and even data storage systems. By implementing redundancy, businesses can minimize downtime and prevent disruptions to their operations.
Investing in redundant server infrastructure may seem like an upfront expense, but it pays off in the long run. Here are some key benefits of investing in redundancy:
- Reduced Downtime: Redundancy ensures that if one component fails, another takes over seamlessly, minimizing downtime.
- Improved Reliability: By having multiple systems in place, the overall reliability of the infrastructure is enhanced, reducing the risk of failure.
- Increased Data Security: Redundant data storage systems protect against data loss due to hardware failure or disasters.
- Enhanced Disaster Recovery: In the event of a natural disaster or other catastrophic event, redundant systems allow for quick recovery and minimal disruption.
- Improved Performance: Redundancy can also improve performance by distributing workload across multiple servers, reducing load on individual systems.
There are different levels of redundancy that businesses can implement, depending on their specific needs and budget. These include:
- Server Redundancy: Having multiple servers that can take over each other’s workloads in case of failure.
- Network Redundancy: Having multiple network connections and pathways to ensure connectivity even if one fails.
- Power Redundancy: Using uninterruptible power supplies (UPS) and backup generators to provide power in the event of a power outage.
- Data Redundancy: Having multiple copies of data stored in different locations to prevent data loss.
When designing a redundant server infrastructure, it’s important to carefully consider the specific requirements of the business. This includes factors such as the type of data being stored, the criticality of the systems, and the budget available. Consulting with experienced IT professionals can help businesses develop a robust and cost-effective redundancy strategy.
Investing in redundant server infrastructure is a strategic decision that can safeguard a business’s operations and ensure long-term success. By mitigating downtime, improving reliability, and enhancing data security, businesses can focus on their core operations knowing that their infrastructure is resilient and dependable.
Ensuring Regular Software Updates and Maintenance
In the ever-evolving landscape of technology, ensuring regular software updates and maintenance is paramount for maintaining the security, stability, and performance of your systems. Neglecting these crucial tasks can expose your organization to a multitude of risks, including security breaches, data loss, and system downtime. This article will delve into the importance of regular software updates and maintenance, outlining the benefits and best practices to effectively manage them.
Why Are Software Updates Essential?
Software updates are like patches that fix vulnerabilities, bugs, and security flaws that can be exploited by malicious actors. These updates often include critical security fixes, performance enhancements, and new features. By installing updates promptly, you are essentially strengthening your defenses against cyberattacks and improving the overall health of your software.
The Benefits of Regular Software Updates
Regular software updates offer a wide range of benefits, including:
- Enhanced Security: Updates patch vulnerabilities and security holes, making your systems more resilient against cyber threats.
- Improved Performance: Updates optimize system performance, leading to faster processing speeds, reduced errors, and smoother operations.
- Increased Stability: Updates address bugs and glitches, ensuring a more stable and reliable system.
- New Features and Functionality: Updates often introduce new features and functionalities, enhancing user experience and productivity.
- Compliance with Regulations: Some industries have strict regulations regarding software updates and security patches. Regular updates help you stay compliant with these regulations.
Best Practices for Software Updates and Maintenance
Implementing effective software update and maintenance practices is crucial for maximizing their benefits. Here are some best practices to consider:
- Establish a Regular Update Schedule: Create a schedule for regular updates, ensuring that all systems and applications are updated on a timely basis. Consider setting automated update schedules to streamline the process.
- Prioritize Critical Updates: Focus on installing critical updates promptly, especially those addressing critical vulnerabilities or security flaws.
- Test Updates Before Deployment: Before deploying updates to your production environment, it’s essential to test them thoroughly in a controlled environment to ensure stability and compatibility.
- Back Up Your Systems: Before installing any update, create backups of your critical data and system configurations to mitigate any potential issues.
- Monitor System Health After Updates: After installing updates, monitor your systems closely to ensure that they are operating as expected and that there are no adverse effects.
Conclusion
In conclusion, regular software updates and maintenance are indispensable for safeguarding your systems, protecting your data, and ensuring optimal performance. By adopting the best practices outlined in this article, you can effectively manage software updates and reap their numerous benefits. Remember, neglecting updates can lead to significant security risks, operational disruptions, and financial losses. By prioritizing updates and maintenance, you are taking proactive steps to secure your digital assets and enhance your organization’s overall security posture.
Monitoring Server Performance and Health

In the ever-evolving landscape of technology, ensuring optimal server performance and health is paramount. Servers, the backbone of modern applications and services, play a crucial role in delivering seamless user experiences. However, maintaining peak performance requires constant vigilance and proactive monitoring. This article delves into the importance of server monitoring, highlighting key metrics to track, best practices, and the advantages of utilizing specialized monitoring tools.
Why Server Monitoring Matters
Server monitoring serves as a vigilant watchdog, providing real-time insights into the well-being and efficiency of your server infrastructure. It empowers administrators to identify potential issues before they escalate into major outages, leading to a range of benefits, including:
- Reduced Downtime: Proactive detection of performance bottlenecks and errors allows for swift remediation, minimizing service interruptions and ensuring high availability.
- Improved User Experience: By maintaining optimal server performance, users enjoy faster load times, smoother application responses, and a more enjoyable experience.
- Enhanced Security: Monitoring tools can detect suspicious activity, such as unauthorized access attempts, enabling prompt security measures to protect sensitive data.
- Cost Optimization: Server monitoring helps identify resource inefficiencies, enabling administrators to optimize resource allocation and reduce unnecessary expenditures.
Key Metrics to Monitor
To gain a comprehensive understanding of server health, it is essential to monitor a range of critical metrics. These include:
- CPU Utilization: Monitors the percentage of processor time dedicated to running processes. High CPU utilization can indicate resource constraints or potential performance issues.
- Memory Usage: Tracks the amount of RAM being used by the server. Excessive memory usage can lead to slowdowns and application crashes.
- Disk Space: Monitors available disk space. Running out of disk space can significantly impact performance and potentially cause service disruptions.
- Network Bandwidth: Measures the rate of data transfer between the server and other devices. High bandwidth utilization can indicate network bottlenecks.
- Response Times: Tracks the time it takes for the server to respond to requests. Slow response times can indicate performance degradation.
- System Logs: Provides detailed information about events occurring on the server, including errors, warnings, and security incidents.
Best Practices for Server Monitoring
Effective server monitoring goes beyond simply collecting data; it requires establishing clear objectives and implementing best practices:
- Establish Baselines: Determine normal operating ranges for key metrics, enabling you to quickly identify deviations and potential problems.
- Set Alerts and Notifications: Configure alerts to notify administrators when metrics exceed predefined thresholds, facilitating prompt intervention.
- Automate Monitoring: Utilize monitoring tools that automate data collection, analysis, and alerting, reducing manual effort and ensuring continuous oversight.
- Regularly Review and Adjust: Periodically review monitoring configurations and thresholds to ensure they remain relevant and effective.
Benefits of Specialized Monitoring Tools
Specialized server monitoring tools offer numerous advantages over manual monitoring methods:
- Real-Time Data: Provide continuous, up-to-the-minute insights into server performance and health.
- Automated Alerts: Send instant notifications to administrators when critical events occur, allowing for swift remediation.
- Comprehensive Metrics: Offer a wide range of metrics to monitor, providing a holistic view of server performance.
- Advanced Analytics: Enable in-depth analysis of performance trends, identifying potential issues before they impact users.
- Scalability and Flexibility: Can adapt to the needs of complex server environments and growing infrastructure.
Conclusion
Server monitoring is an indispensable aspect of ensuring optimal server performance and health. By implementing effective monitoring practices and utilizing specialized tools, organizations can proactively identify and resolve issues, minimizing downtime, enhancing user experiences, optimizing resource allocation, and safeguarding sensitive data. Investing in comprehensive server monitoring is a strategic decision that pays dividends in terms of improved reliability, efficiency, and overall business success.
Developing an Incident Response Plan for Downtime Events
Downtime events can be costly and disruptive to any organization. They can lead to lost revenue, damaged reputation, and decreased customer satisfaction. It is therefore critical for organizations to have a comprehensive and well-tested incident response plan in place to minimize the impact of downtime events.
An incident response plan is a documented process that outlines the steps that an organization will take in the event of a downtime event. It should include a clear chain of command, communication protocols, and a list of responsible personnel. The plan should also include detailed procedures for identifying the root cause of the downtime event, containing the damage, restoring service, and preventing future incidents.
Key Steps to Developing an Incident Response Plan
Developing an incident response plan involves several key steps:
- Identify Potential Downtime Events: The first step is to identify the potential downtime events that could affect the organization. This should include both internal and external threats, such as power outages, natural disasters, cyberattacks, and hardware failures.
- Develop a Communication Plan: A communication plan is essential for ensuring that all stakeholders are informed about the incident. This plan should include procedures for notifying customers, employees, and other relevant parties.
- Establish a Chain of Command: It is essential to have a clear chain of command for incident response. This will ensure that decisions are made quickly and efficiently.
- Develop Response Procedures: Response procedures should be detailed and specific. These procedures should outline the steps that should be taken in the event of each potential downtime event.
- Test and Improve the Plan: It is crucial to test the incident response plan regularly. This will ensure that the plan is up-to-date and that all personnel are familiar with their roles and responsibilities.
Benefits of an Incident Response Plan
A well-developed incident response plan offers numerous benefits, including:
- Reduced downtime
- Improved customer satisfaction
- Enhanced brand reputation
- Increased operational efficiency
- Reduced financial losses
In conclusion, an incident response plan is an essential component of any organization’s risk management strategy. By developing a comprehensive and well-tested plan, organizations can significantly reduce the impact of downtime events and protect their business.